FT(Fault Tolerance) 작동 원리
VMware FT는 HA(High Availibility) 기능이 제공할 수 있는 수준을 넘어서서 더 높은 고가용성을 요구하는 미션 크리티컬한 서비스를 작동시켜야 할 경우 FT가 바로 그 대안이 될 수 있다. FT의 작동 배경을 간단하게 소개하면 다음과 같다. 우선 가상 머신에게 FT를 설정하게 되면, 해당 가상 머신은 원본(Primary) 가상 머신으로 선정이 되고 원본 가상 머신의 디스크 파일을 같이 공유하여 바라보게 되는 복제(Secondary) 가상 머신이 생성된다. 이때 복제 가상 머신은 VMotion의 기법을 이용하여 생성되며 HA 클러스터로 구성된 ESXi 서버 내에서도 원본 가상 머신이 작동되고 있지 않는 다른 ESXi 서버 위에 생성된다. VMkernel은 원본 가상 머신에서 일어나는 모든 CPU 명령과 I/O를 저장하여 복제 가상 머신에 그대로 전달한다.
외부에서 바라볼 때는 원본 가상 머신만 존재하며 원본 가상 머신을 통해서만 I/O를 전달할 수 있다. 복제 가상 머신은 외부에 드러나지 않으며 모든 I/O 처리는 기본적으로 원본 가상 머신을 통해서만 이루어진다. 만일 원본 가상 머신이 작동되고 있는 물리적인 서버에서 장애가 발생할 경우, 복제 가상 머신은 즉각 원본 가상 머신 역할을 도맡게 되어 중단 없이 I/O 처리를 계속 진행하게 되고 새로운 복제 가상 머신이 다른 물리적인 ESXi 서버 위에서 또다시 VMotion 기술을 통해 재생성된다. 그런데 여기서 핵심은 바로 어떻게 해서 원본 가상 머신과 복제 가상 머신이 항상 동일한 내용을 공유할 수 있는가 여부이다. 물리적인 시스템에서 순간적으로 장애가 발생하였을 경우 그 장애 시점 이후부터 전혀 I/O 중단 없이 복제 가상 머신이 그 I/O를 도맡아 처리할 수 있어야 할 것이다. VMware에서는 이것을 Record/Replay라는 기법을 통해 해결하고 있다.
Record/Replay
일반적으로 컴퓨터에서 CPU가 명령을 실행하는 단계를 보통 5단계로 나누어서 설명한다 명령을 끌어오고, 디코딩하고, 실행하며, 전송하고 마지막으로 결괏값을 레지스터와 캐시 등에 저장한다. CPU가 이렇게 일련의 정해진 절차를 거쳐 규칙적으로 명령을 처리하지만 주변 장치들이 개입할 경우에는 그렇지가 않다. CPU가 어떤 명령을 실행하여 처리하고 있는 도중에 느닷없이 키보드 입력이나 마우스 이동과 같은 아주 간단한 하드웨어 인터럽트부터, 네트워크 패킷이 입력되거나 디스크 읽기, 그리고 타이머 이벤트와 같은 인터럽트들이 중간에 끼어들게 된다. 이러한 인터럽트들은 말 그대로 끼어들기이므로 CPU 입장에서는 하던 일을 멈추고 이러한 인터럽트들을 처리해 주어야 한다. 한마디로 예측 불가능한 이벤트들이다. FT에서의 핵심은 바로 이러한 예측 불가능한 인터럽트들이 원본 가상 머신에게 발생하였을 경우 어떤 방식으로 복제 가상 머신에게 전달해 줄 것인가이다. 무중단 시스템 구축의 어려움이 바로 이러한 문제점이었다. 원본 가상 머신에서 일어나는 이러한 모든 인터럽트들을 어떻게 하면 복제 가상 머신에게 그대로 다 전달해 줄 수 있을지가 바로 핵심이었던 것이었다.
Record/Replay기술은 바로 이것을 해결하기 위함이다.
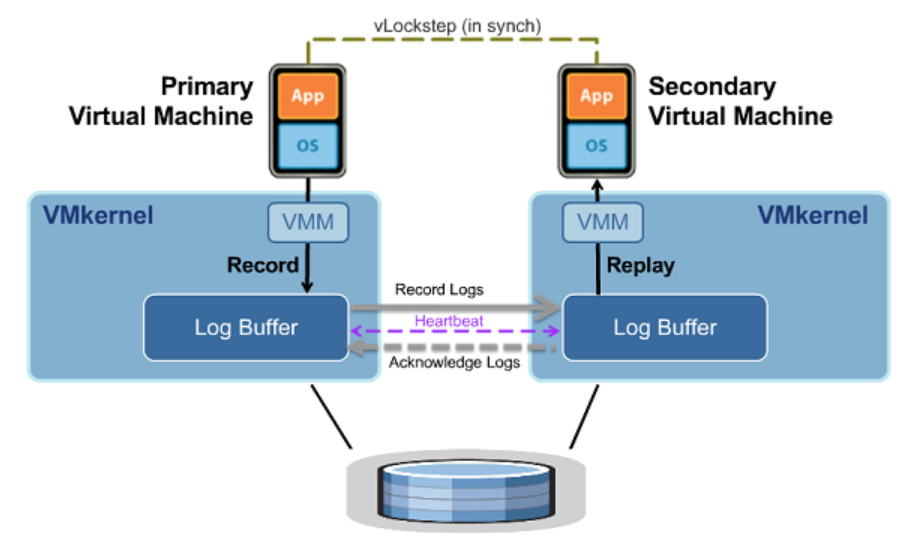
우선 VMkernel은 원본 가상 머신에서 발생하는 예측 불가능한 인터럽트들(마우스 이동, 키보드 입력, 네트워크 패킷 입력 등)을 로그 버퍼에 전부 기록(Record)해둔다. VMkernel은 이 로그 버퍼를 milliseconds 단위로 매우 빠르게 저장하고 비우게(flush) 된다. 로그 버퍼를 비울 경우 FT 로그 전용 네트워크를 통해 복제 가상 머신이 작동되고 있는 다른 ESXi 서버의 로그 버퍼로 저장해 둔 로그를 전송한다. 로그를 전송받은 복제 가상 머신 측의 VMkernel은 전송된 로그를 바탕으로 그대로 복제 가상 머신에게 재현(Replay)시킨다. 즉, 복제 가상 머신에서 프로세스가 실행되고 처리되는 중간에 그 인터럽트 이벤트들을 끼워 넣어주는 식으로 재현시키는 것이다.
원본 가상 머신에서 발생한 인터럽트를 Record 한 다음 복제 가상 머신의 프로세스에 끼워 넣어 Replay 하게 되면 아무리 빠르게 재현한다 할지라도 자연의 법칙을 넘어설 수는 없으며, 원본 가상 머신과 복제 가상 머신 사이에서는 지연시간이 발생할 수밖에 없다. 이 지연 시간은 FT 전용 네트워크의 지연시간을 의미하는 것이 아니며, 원본 가상 머신과 복제 가상 머신 간의 프로세스 처리 지연시간을 의미한다. 이러한 지연 시간은 FT를 구성한 다음 원본 가상 머신에서 vLockstep Interval이라는 값으로 확인할 수 있다.
한편 원본 가상 머신에서 발생하는 로그를 전송하기 위해서 FT 전용 네트워크가 필요한다. 이 FT 전용 네트워크의 대역폭 크기는 크면 클수록 좋으며 최소 1Gbps 전용 네트워크는 필수이다.
이러한 Record/Replay 기술이 실제로 구현되기 위해서는 VMkernel 하이퍼바이저만의 S/W 기술만으로는 불가능하며 인텔과 AMD CPU의 하드웨어 기술 도움을 받아야 한다. 바로 하드웨어 CPU 가상화 기술인 Inter VT-x와 AMD-V 기능이 그것이며, FT 성능과 관련한 몇 가지 프로세서 익스텐션 값들이 추가되어야 했기 때문에 모든 인텔과 AMD CPU에서 FT 기능을 사용할 수 있는 것은 아니다. 때문에 FT를 사용할 수 있는 CPU의 종류를 잘 확인해서 구현해야 할 것이다.
장애감지 방법
그렇다면 FT는 어떻게 해서 ESXi 서버의 장애를 감지하게 되는 것일까? FT를 구성할 경우 FT 전용 네트워크를 생성해야 한다. 이때 VMotion과 같이 FT 전용 네트워크에도 IP 주소를 입력하게 된다. 이 IP 주소를 통해서 heartbeat 프레임을 던지게 되는데 만일 0.5초 안에 응답이 없을 경우 ESXi 서버에 장애가 발생한 것으로 간주하며, 만일 원본 가상 머신 측의 ESXi 서버라면 복제 가상 머신이 즉각 원본 가상 머신을 도맡게 된다. 반대로 복제 가상 머신 측의 ESXi 서버에 장애가 발생한 것이라면 HA 클러스터 내의 다른 ESXi 서버 위에 새로운 복제 가상 머신을 생성한다.
하드웨어에 실제 장애가 발생하여서 heartbeat 통신 유무를 판별하기 위해서 VMware는 rename 방식을 통해 판별한다.
Heartbeat 프레임에 응답이 없을 경우 ESXi 서버는 특정된 공통 파일에 대하여 이름 변경(rename)을 시도하게 된다. 하드웨어에 장애가 발생하였다면 파일에 접근이 불가능하고 이름 변경도 안 되는 점을 이용하는 것이다. 파일 이름 변경이 가능한 ESXi 서버 위에서 작동되는 가상 머신이 복제 가상 머신일 경우 FT는 즉각적으로 복제 가상 머신을 원본 가상 머신으로 대체한다.
'⫸VMware' 카테고리의 다른 글
| DRS/DPM 기능 원리 (0) | 2022.10.19 |
|---|---|
| HA 개요 및 작동 원리 (0) | 2022.10.14 |
| Storage VMotion 작동 원리 (0) | 2022.10.13 |
| VMotion 작동 원리 (0) | 2022.10.12 |
| 가상 머신 스냅샷 (0) | 2022.10.11 |